This blog post is written as an overview and summary of our NeurIPS 2024 paper, Fundamental Limits of Prompt Compression: A Rate-Distortion Framework for Black-Box Language Models
What is Prompt Compression?
In words, the goal of prompt compression is to distill the context of a target large language model (LLM) into a smaller representation such that the output generated by the LLM with the smaller context is similar in meaning to a ground truth reference that was generated using the full context. For example, in traditional prompting we give the full context as a prompt \(x\), in addition to a query \(q\), from which the LLM generates a response. The figure below is a visual representation of this procedure.
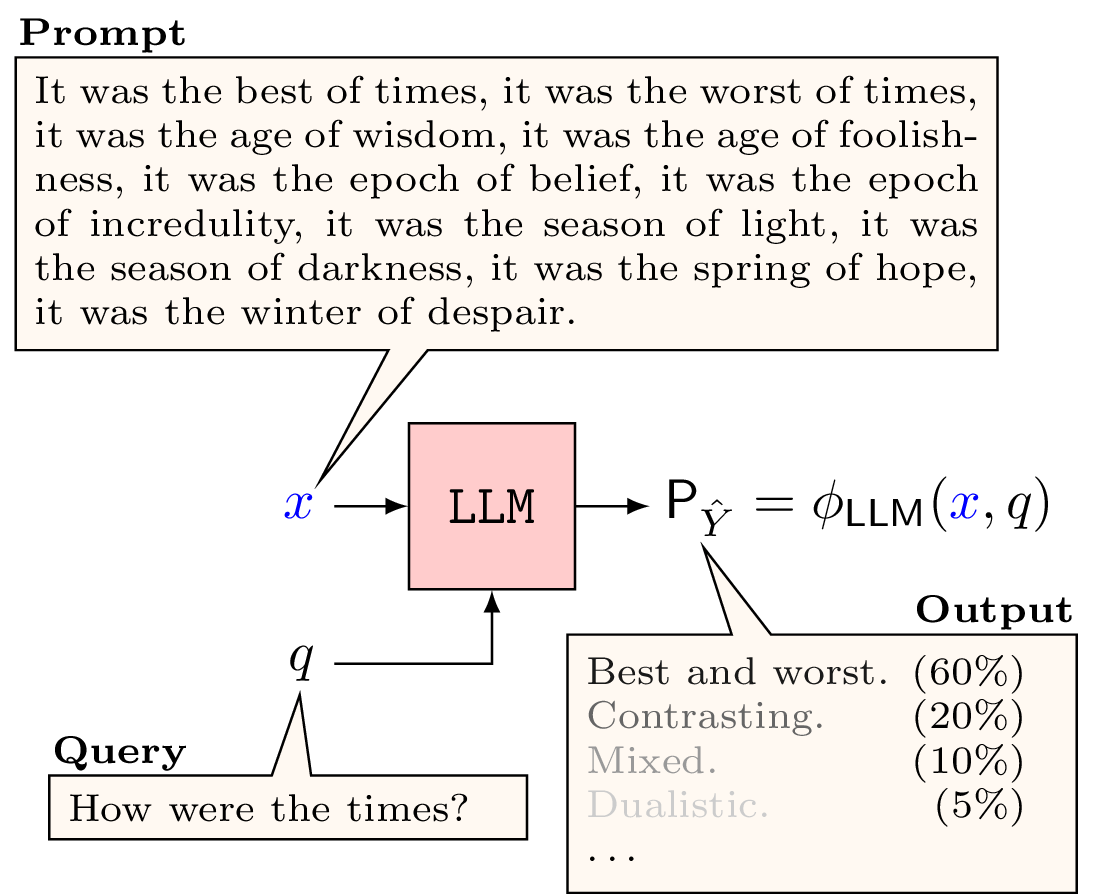
In prompt compression, we introduce one additional step to modify the prompt before giving it to the LLM. As shown in the figures below, a compressor \(\texttt{comp}\) converts the prompt \(x\) into a compressed prompt \(m\) such that, ideally, (1) \(m\) carries sufficient information for answering the query, and (2) \(m\) is much smaller in length than \(x\).
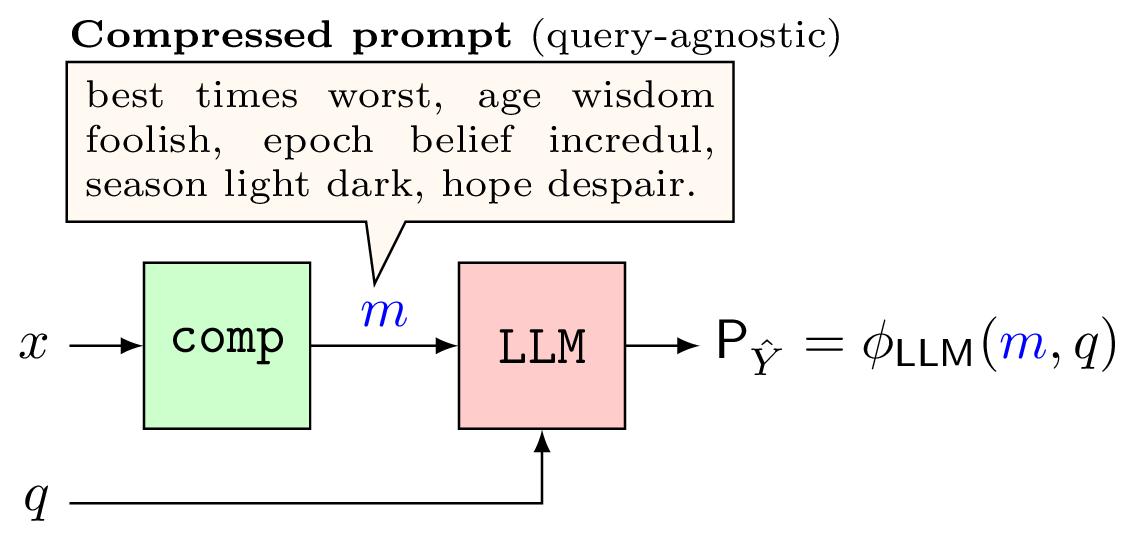
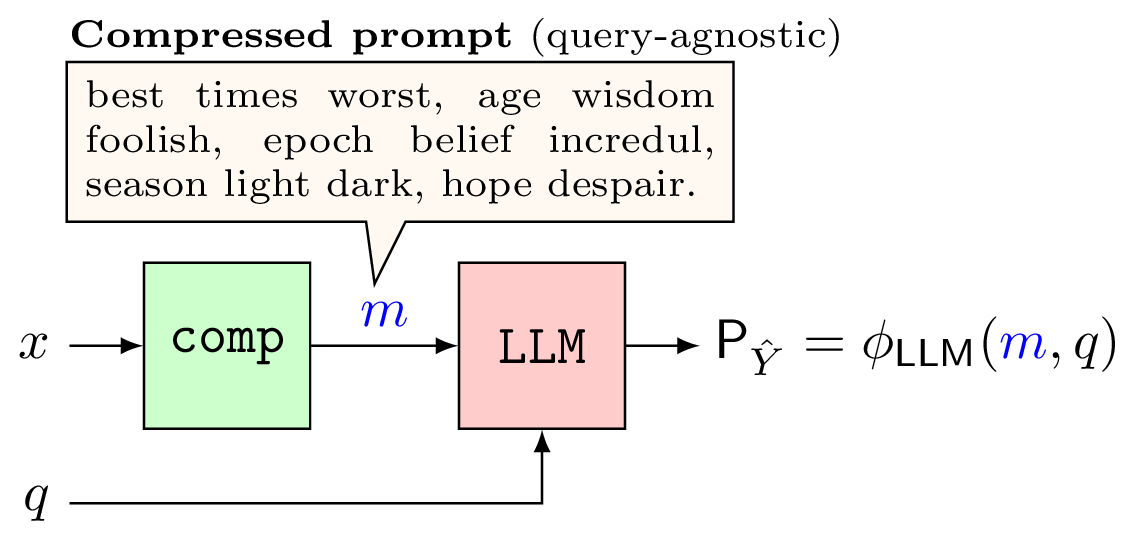
As shown, there are two cases to consider in the prompt compression problem. In the query-agnostic case, the query \(q\) is made available only to the decoder, and in the query-aware case, \(q\) is available to the encoder as side-information for compressing the prompt into \(m\). Intuitively, we expect that \(m\) carries only the relevant information to answer \(q\) (and is therefore also shorter in length) in the query-aware case as opposed to the query-agnostic case.
Why does prompt compression matter?
A key motivating factor of prompt compression is that it shortens the sequence length of the input, which will reduce the time and memory costs associated with LLM inference. This will be true for any architecture, no matter how efficient it already is, since the cost of running inference on a sequence model is a function of the length of the input sequence.
During the incpetion of prompt compression, a key motivating factor was to reduce the size of the input as a means to allow the entire prompt to fit into the context of the LLM, which had much shorter context lengths at the time. Since then, a lot of progress has been made in extending the context length of LLMs, of which should be sufficient for fitting most prompts. However, performance degradation when the long context is used has been observed; this phenomenon is known as the “lost in the middle” issue [1]. This issue may be partially or fully mitigated by first compressing the prompt so that the LLM can make better use of its context [2].
Our Setup
As illustrated in these examples, we consider the compressed prompt \(m\) to be a subsequence of tokens of the original prompt \(x\). This approach, sometimes called token pruning, results in \(m\) being a hard-prompt, i.e., a prompt consisting only of tokens. Some methods that compress into hard-prompts are Selective Context [3], LLMLingua [4], LongLLMLingua [2], and LLMLingua-2 [5]. Alternatively, one may compress such that \(m\) is a soft-prompt, i.e., a prompt as a sequence of embedding vectors (which do not map to tokens) as input to the target LLM; such methods include Gist Tokens [6], AutoCompressor [7], In-Context Auto-enocder [8]. In our work, we focus on studying methods that compress into hard-prompts as it grants the flexibility to consider a black-box LLM as the target LLM. Using a black-box model is desired since (1) many LLMs, especially the most performant among them, are closed-source such that a user can only make inference calls to the model and observe the generated text, and (2) we make no assumptions about the LLM itself and therefore our proposed framework is general. Any soft-prompt compression method is not compatible with black-box models because those methods require specialized fine-tuning on soft-prompts, modifications to the architecture or token vocabulary, that the model can accept embeddings as input, or some combination of these. While soft-prompt compression methods are useful, we wanted to study the prompt compression problem with the widest applicability to how most people use LLMs, i.e., inferencing an LLM by giving it a hard-prompt.
As a result, the following list are our main contributions:
- We formalize the prompt-compression problem with a rate-distortion framework, and we use this framework to compute the rate-distortion trade-off for the optimal query-agnostic and query-aware prompt compressors.
- We curate small-scale datasets to determine the rate-distortion trade-off among existing prompt compression methods and compare them with the optimal compressors.
- We adapt an existing method, LLMLingua-2, into a query-aware, variable-rate prompt compression method, which we call “LLMLingua-2 Dynamic,” to help close the gap between existing methods and optimality.
Our Results
We conduct our experimental studies on a dataset consisting of binary string prompts, natural language queries, and their respective answers. While each method provides it’s own algorithm, the target LLM is always the same model (a Mistral-7B-Instruct-v0.2 model for our experiments). The rate-distortion curves of all methods are provided below.
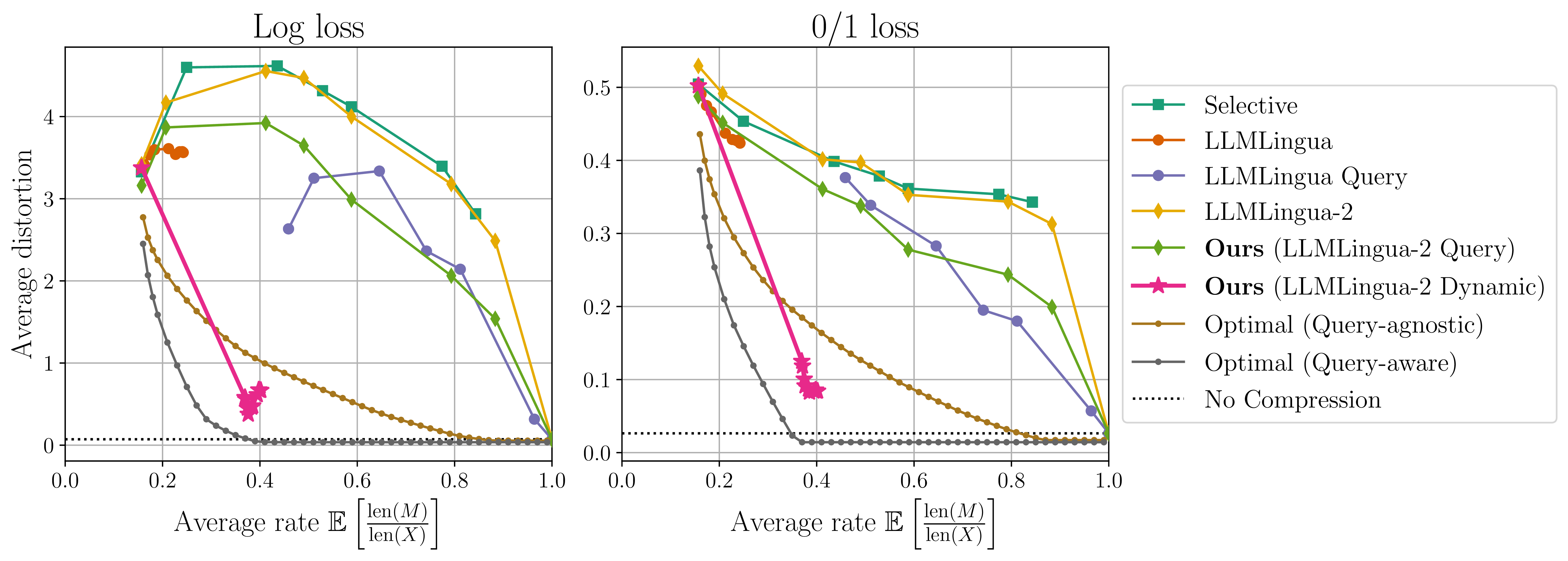
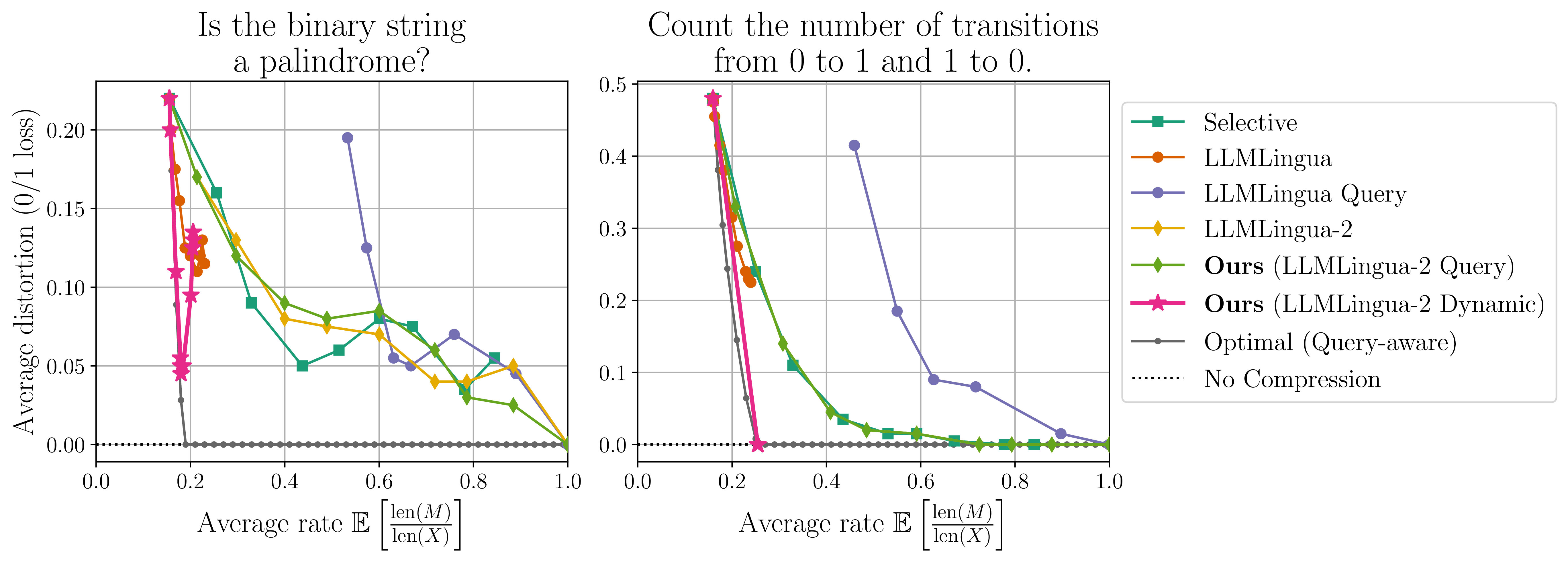
Our LLMLingua-2 Dynamic method outperforms all existing methods on this dataset and is the only method which can outperform the optimal query-agnostic prompt compressor. Interestingly, the optimal prompt compressors are also able to achieve a lower average distortion than the “No Compression” (standard prompting where \(x\) is given directly to the LLM) result.
LLMLingua-2 Dynamic Partially Closes the Gap
We also highlight that LLMLingua-2 Dynamic is able to match the performance of the optimal query-aware prompt compressor for certain queries and rates, as shown in the following figure.
Experiments on Natural Language Prompts
Finally, we extend our results to a small dataset consisting of prompts, queries, and answers that are all natural language.
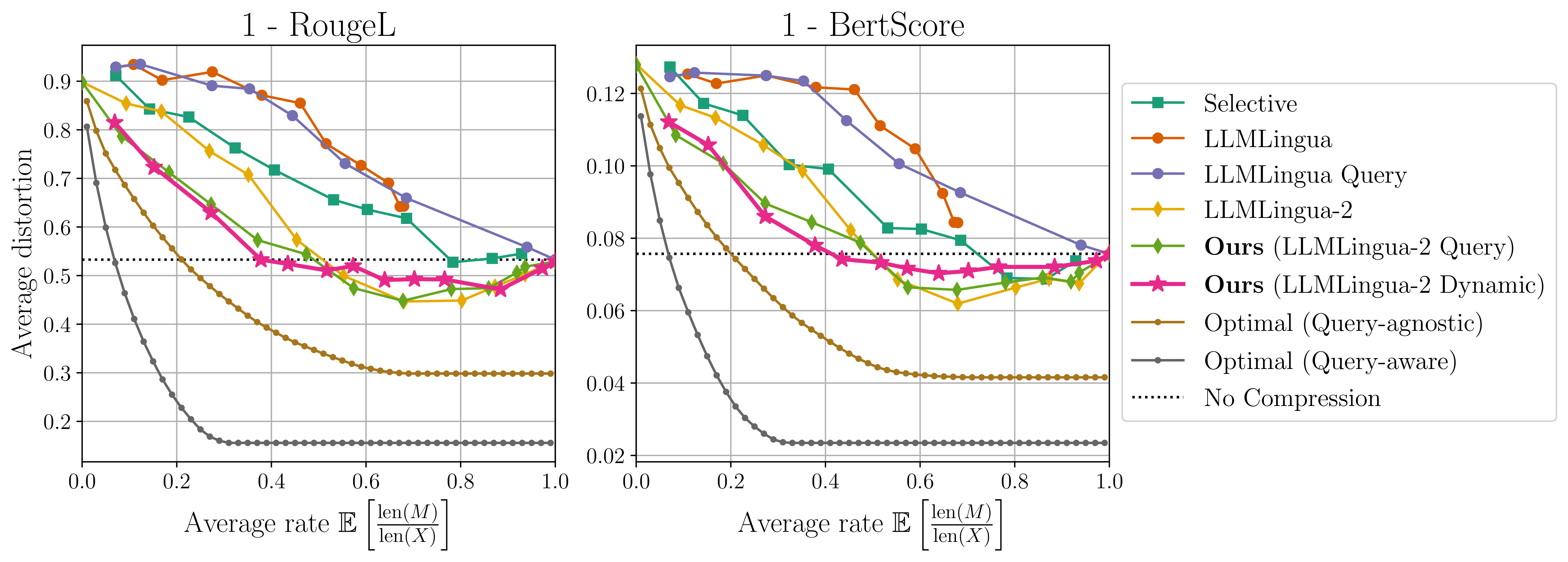
Again, we see that the optimal prompt compressors can achieve a significantly lower average distortion than the “No Compression” result, showing that prompt compression can yield better performance than standard prompting. This result is particularly interesting because the dataset we use has short prompts of no more than 15 tokens. Hence, this improvement in performance arrives purely from the choice of the compressed prompt itself, and is not related to improvements due to remedying the “lost in the middle” issue, which may lead to even better performance for long contexts. The gaps between existing methods and the optimal compressors are also large, although for rates greater than 0.5 existing methods can also achieve lower average distortion than the “No Compression” result. For rates less than 0.5, LLMLingua-2 Dynamic achieves the best performance.
Conlcusions and Future Work
Our work introduces a rate-distortion framework for the prompt compression problem, which is used to compute the rate-distortion curves of the optimal prompt compressors. We show that there is a large gap between existing prompt compression methods and optimality, and we partially close the gap with our adapted LLMLingua-2 Dynamic method.
As future work, it is important to scale our analysis to larger datasets. The main challenge here is gathering the distortion values from the LLM outputs over all the compressed prompts, as this will require at least \(2^{n}\), where \(n\) is the length of the input prompt, inference calls for each prompt. Much work is also needed to fully close the gap between our method and the optimal prompt compressors.
References
[1] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. ACL, Februaru 2024.
[2] LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu. Preprint, October 2024.
[3] Compressing Context to Enhance Inference Efficiency of Large Language Models, Yucheng Li, Bo Dong, Frank Guerin, Chenghua Lin. EMNLP, December 2023.
[4] LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models, Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu. EMNLP, December 2023.
[5] LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression, Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, Dongmei Zhang. Preprint, March 2024.
[6] Learning to Compress Prompts with Gist Tokens, Jesse Mu, Xiang Lisa Li, Noah Goodman. December, 2023.
[7] Adapting Language Models to Compress Contexts, Alexis Chevalier, Alexander Wettig, Anirudh Ajith, Danqi Chen. EMNLP, December 2023.
[8] In-context Autoencoder for Context Compression in a Large Language Model, Tao Ge, Hu Jing, Lei Wang, Xun Wang, Si-Qing Chen, Furu Wei. ICLR, May 2024.